Prompt tuning, in which a base pretrained model is adapted to each task via conditioning on learned prompt vectors,
has emerged as a promising approach for the efficient adaptation of large language models to multiple downstream tasks.
However, existing methods typically learn soft prompt vectors from scratch,
and it has not been clear how to exploit the rich cross-task knowledge in task-specific prompt vectors to improve performance on target downstream tasks.
In this paper, we propose multitask prompt tuning (MPT),
which first learns a single transferable prompt by decomposing and distilling knowledge from multiple task-specific source prompts.
We then learn multiplicative low rank updates to this shared prompt to efficiently adapt it to each downstream target task.
Extensive experiments on 21 NLP datasets demonstrate that our proposed approach outperforms the state-of-the-art methods,
including the full finetuning baseline in some cases, despite only tuning 0.035% as many task-specific parameters.
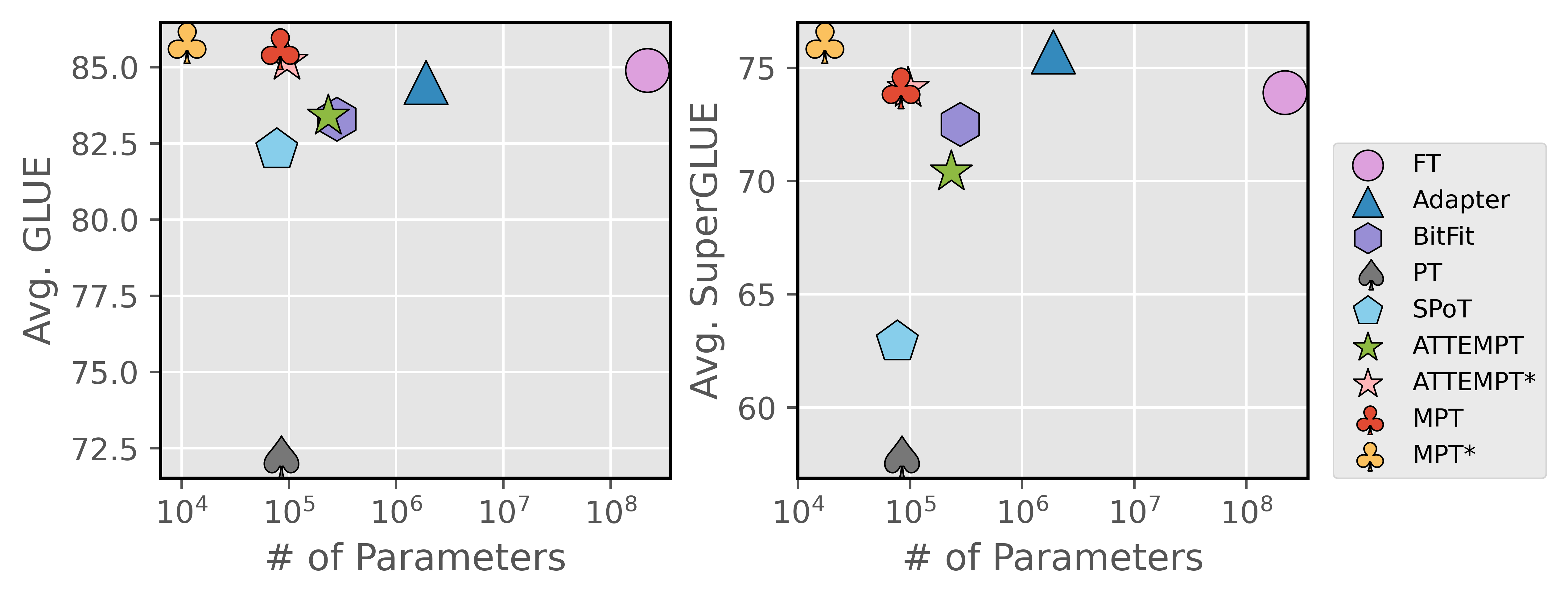
Qualitative Results
Performance on GLUE and SuperGLUE shows great parameter efficiency of MPT, which outperforms all the existing prompt tuning methods and full model finetuning (FT), despite updating much fewer task-specific parameters.