Publications
*=co-first author | +=corresponding author | Google Scholar
2026
FIRE-Bench: Evaluating Research Agents on the Rediscovery of Scientific Insights
ICML 2026
The first benchmark for reliably evaluating research agents on full-cycle scientific (re-)discovery, with verifiable evaluation of insight rediscovery.
Decentralized Arena: Towards Democratic and Scalable Automatic Evaluation of Language Models
ACL 2026
Democratic LLM benchmarking where models judge each other for scalable and fair evaluation.
A Foundation Model of Cancer Genotype Enables Precise Predictions of Therapeutic Response
Cancer Discovery 2026 In Press IF: 33.3
The first genomics foundation model of cancer mutations, enabling precise predictions of therapeutic response.
Nabla Reasoner: LLM Reasoning via Test-Time Gradient Descent in Textual Space
ICLR 2026
A novel approach to LLM reasoning through test-time gradient descent operations in textual space.

MemProbe: Probing Long-Term Agent Memory via Hidden User-State Recovery
In submission
A framework that probes long-term agent memory by recovering the hidden user states it has implicitly absorbed.
Demystifying Training-Time Augmentation for Data-Constrained Language Model Pretraining
In submission
A systematic study of training-time data augmentation for pretraining language models in the data-constrained, compute-abundant regime.

Leveraging Latent Visual Reasoning in Silence
In submission
Vision-language reasoning through silent latent computation, decoupling internal visual deliberation from the generated answer.

FlashEvolve: Accelerating Agent Self-Evolution with Asynchronous Stage Orchestration
In submission
FlashEvolve turns synchronous agent evolution loops (GEPA, ACE, Meta-Harness) into asynchronous worker pipelines for a 3.5 to 4.9x acceleration.

TritonDFT: Automating DFT with a Multi-Agent Framework
In submission
A multi-agent framework for automating Density Functional Theory (DFT) calculations.

Pancake: Hierarchical Memory System for Multi-Agent LLM Serving
In submission
A hierarchical memory system designed for efficient multi-agent LLM serving.

CellMaster: Collaborative Cell Type Annotation in Single-Cell Analysis
In submission
A collaborative AI scientist agent for automated cell type annotation in single-cell transcriptomics analysis.

Learning Modal-mixed Chain-of-thought Reasoning with Latent Embedding
In submission
Learning chain-of-thought reasoning that seamlessly mixes different modalities through latent embeddings.

Mind2Dialogue: State-Aware User Simulation for Theory-of-Mind and Personalization
In submission
A state-aware user simulator for enhancing theory-of-mind and personalization in LLMs.

HypoEvolve: When Genetic Algorithm Meets Multi-Agents to Accelerate Hypothesis Discovery
In submission
A novel approach combining genetic algorithms with multi-agent systems for automated scientific hypothesis discovery.

PuzzRL: Piecing Together Concurrent RL Pipelines for Cost-Efficient LLM Post-Training
In submission
PuzzRL turns concurrent RL pipelines into a new parallelism dimension, multiplexing complementary sub-stages to reclaim wasted GPU cycles.

TreeScientist: Budget-Constrained Exploration for Autonomous Research
In submission
A budget-aware tree-structured exploration strategy that lets autonomous research agents allocate compute and trials adaptively.
2025
scPilot: Large Language Model Reasoning Toward Automated Single-Cell Analysis and Discovery
NeurIPS 2025
The first omics-native reasoning agent that grounds LLMs in raw single-cell data for automated analysis and biological discovery.

Atlas-Guided Discovery of Transcription Factors for T Cell Programming
Nature 2025 In Press
Contributed TaijiChat, a Paper Copilot for multi-omics discovery of transcription factors for T cell programming.
DeepPersona: A Generative Engine for Scaling Deep Synthetic Personas
Spotlight at NeurIPS 2025 LAW
A generative engine for creating deep synthetic personas that enable realistic human simulation at scale.
Self-MoE: Towards Compositional Large Language Models with Self-Specialized Experts
ICLR 2025
Transforms monolithic LLMs into modular systems with self-specialized experts for compositional capabilities.
2024
Dynamic Rewarding with Prompt Optimization Enables Tuning-free Self-Alignment of Language Models
EMNLP 2024 (Main, Long)
First tuning-free method for self-aligning LLMs with human preferences through dynamic rewarding and prompt optimization.
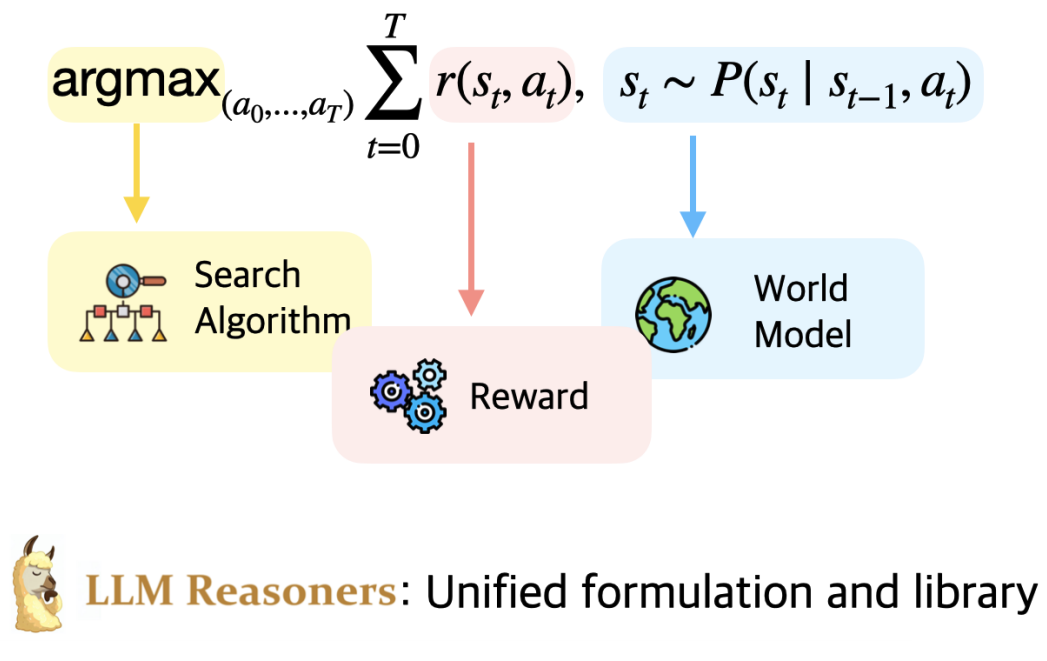
LLM Reasoners: New Evaluation, Library, and Analysis of Step-by-Step Reasoning with Large Language Models
COLM 2024 2.3k+ GitHub Stars
A library enabling LLMs to conduct complex reasoning with advanced algorithms, approaching multi-step reasoning as planning with world models and rewards.
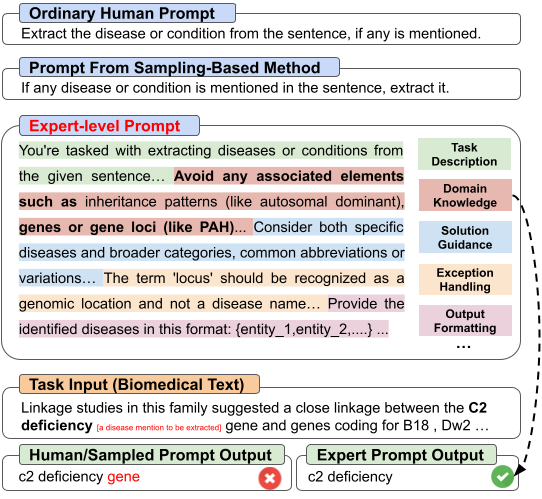
PromptAgent: Strategic Planning with Language Models Enables Expert-level Prompt Optimization
ICLR 2024
First principled framework to formalize API-based prompt optimization as planning with state, action, and reward; first to benchmark exploration efficiency and show transferability of optimized prompts.

GPT Is Becoming a Turing Machine: Here Are Some Ways to Program It
ICLR 2024 AGI Workshop
Through appropriate prompting, GPT models can perform iterative behaviors to execute (not just write) programs with loops, including algorithms like logical deduction, bubble sort, and LCS.
2023

Reasoning with Language Model is Planning with World Model
EMNLP 2023 (Oral, Main) Featured in State of AI Report 2023
RAP reformulates LLM reasoning as a planning problem, incorporating external world models and principled planning for the best balance of exploration vs exploitation.

ToolkenGPT: Augmenting Frozen Language Models with Massive Tools via Tool Embeddings
NeurIPS 2023 Oral (Top 2%) Best Paper @ SoCal NLP 2023
Augments LLMs with massive tools/APIs by representing tools as tokens ("toolken"), enabling tool calls as naturally as generating words. Plugging in new tools is as easy as learning embeddings.

ThinkSum: Probabilistic Reasoning Over Sets Using Large Language Models
ACL 2023 (Main)
A two-stage probabilistic inference paradigm to improve LLMs' reasoning over multiple objects through Think (retrieval) and Sum (aggregation), beating chain-of-thought on hard BIG-bench tasks.

Multitask Prompt Tuning Enables Parameter-Efficient Transfer Learning
ICLR 2023
Multitask Prompt Tuning (MPT) exploits rich cross-task knowledge for efficient and generalizable transfer learning through novel prompt decomposition and distillation.

Frustratingly Simple Entity Tracking with Effective Use of Multi-Task Learning Models
EACL 2023 (Main)
Shows how to transfer multi-task knowledge from pre-training to niche downstream tasks like entity tracking, achieving SOTA by fine-tuning T5 with specialized QA prompts and task-specific decoding.
Roll Up Your Sleeves: Working with a Collaborative and Engaging Task-Oriented Dialogue System
SIGDIAL 2023
A collaborative and engaging task-oriented dialogue system for multi-step cooking and home improvement tasks.
2022

Coherence Boosting: When Your Pretrained Language Model is Not Paying Enough Attention
ACL 2022 (Main, Long, Oral)
Demonstrates that LLMs have insufficiently learned the effect of distant words on next-token prediction. Coherence Boosting increases an LM's focus on long context, greatly improving NLG and NLU tasks.

Knowledge Transfer between Structured and Unstructured Sources for Complex Question Answering
NAACL 2022 SUKI Workshop
Studies knowledge transfer for multi-hop reasoning between structured (KB) and unstructured (text) knowledge. SimultQA unifies KBQA and TextQA to study how reasoning transfers between knowledge sources.

Toward Knowledge-Centric NLP: Acquisition, Representation, Transfer, and Reasoning
Ph.D. Dissertation, The Ohio State University, 2022
Doctoral dissertation on building foundations for knowledge-centric AI systems through acquisition, representation, transfer, and reasoning.
2021

Bootstrapping a User-Centered Task-Oriented Dialogue System
Alexa Prize TaskBot Challenge 2021 3rd Place Winner
TacoBot, a task-oriented dialogue system for cooking and home improvement tasks. Proposes data augmentation methods including GPT-3 simulation to bootstrap neural dialogue systems into new domains.

Modeling Context Pair Interaction for Pairwise Tasks on Graphs
WSDM 2021 (Long)
Explicitly models context interactions for pairwise prediction on graphs through node-centric and pair-centric perspectives, with pre-trained pair embeddings to facilitate pair-centric modeling.
2020

Rationalizing Medical Relation Prediction from Corpus-level Statistics
ACL 2020 (Main, Long)
A self-interpretable framework to rationalize neural relation prediction based on corpus-level statistics, inspired by human cognitive theory about recall and recognition, providing structured knowledge triplets as rationales.

Graph Embedding on Biomedical Networks: Methods, Applications, and Evaluations
Bioinformatics, Volume 36, Issue 4, February 2020
Benchmarks 11 representative graph embedding methods on five important biomedical tasks, verifying effectiveness and providing general guidelines for their usage.
2019

SurfCon: Synonym Discovery on Privacy-Aware Clinical Data
KDD 2019 (Research Track, Long, Oral)
Discovers structured knowledge, synonyms, from privacy-aware clinical text corpus, leveraging both surface form and context information to discover out-of-distribution synonyms.
Before 2019

A Comprehensive Study of StaQC for Deep Code Summarization
KDD 2018 Deep Learning Day Spotlight
Examines three popular datasets mined from Stack Overflow on code summarization, showing that StaQC achieves substantially better results.

Hessian Regularized Sparse Coding for Human Action Recognition
MMM 2015
Proposes Hessian regularized sparse coding (HessianSC) for action recognition, preserving local geometry and steering sparse coding linearly along the data manifold.
Agentic Reasoning and Planning with World Models
Leveraging Latent Visual Reasoning in Silence
In submission
Vision-language reasoning through silent latent computation, decoupling internal visual deliberation from the generated answer.
Nabla Reasoner: LLM Reasoning via Test-Time Gradient Descent in Textual Space
ICLR 2026
A novel approach to LLM reasoning through test-time gradient descent operations in textual space.
Learning Modal-mixed Chain-of-thought Reasoning with Latent Embedding
In submission
Learning chain-of-thought reasoning that seamlessly mixes different modalities through latent embeddings.
scPilot: Large Language Model Reasoning Toward Automated Single-Cell Analysis and Discovery
NeurIPS 2025
The first omics-native reasoning agent that grounds LLMs in raw single-cell data for automated analysis and biological discovery.
CellMaster: Collaborative Cell Type Annotation in Single-Cell Analysis
In submission
A collaborative AI scientist agent for automated cell type annotation in single-cell transcriptomics analysis.
LLM Reasoners: New Evaluation, Library, and Analysis of Step-by-Step Reasoning with Large Language Models
COLM 2024 2.3k+ GitHub Stars
A library enabling LLMs to conduct complex reasoning with advanced algorithms, approaching multi-step reasoning as planning with world models and rewards.
PromptAgent: Strategic Planning with Language Models Enables Expert-level Prompt Optimization
ICLR 2024
First principled framework to formalize API-based prompt optimization as planning with state, action, and reward; first to benchmark exploration efficiency and show transferability of optimized prompts.
Reasoning with Language Model is Planning with World Model
EMNLP 2023 (Oral, Main) Featured in State of AI Report 2023
RAP reformulates LLM reasoning as a planning problem, incorporating external world models and principled planning for the best balance of exploration vs exploitation.
ToolkenGPT: Augmenting Frozen Language Models with Massive Tools via Tool Embeddings
NeurIPS 2023 Oral (Top 2%) Best Paper @ SoCal NLP 2023
Augments LLMs with massive tools/APIs by representing tools as tokens, enabling tool calls as naturally as generating words. Plugging in new tools is as easy as learning embeddings.
ThinkSum: Probabilistic Reasoning Over Sets Using Large Language Models
ACL 2023 (Main)
A two-stage probabilistic inference paradigm to improve LLMs' reasoning over multiple objects through Think (retrieval) and Sum (aggregation), beating chain-of-thought on hard BIG-bench tasks.
GPT Is Becoming a Turing Machine: Here Are Some Ways to Program It
ICLR 2024 AGI Workshop
Through appropriate prompting, GPT models can perform iterative behaviors to execute (not just write) programs with loops, including algorithms like logical deduction, bubble sort, and LCS.
Knowledge-Structured Representation Learning
Multitask Prompt Tuning Enables Parameter-Efficient Transfer Learning
ICLR 2023
Multitask Prompt Tuning (MPT) exploits rich cross-task knowledge for efficient and generalizable transfer learning through novel prompt decomposition and distillation.
Coherence Boosting: When Your Pretrained Language Model is Not Paying Enough Attention
ACL 2022 (Main, Long, Oral)
Demonstrates that LLMs have insufficiently learned the effect of distant words on next-token prediction. Coherence Boosting increases an LM's focus on long context, greatly improving NLG and NLU tasks.
Modeling Context Pair Interaction for Pairwise Tasks on Graphs
WSDM 2021 (Long)
Explicitly models context interactions for pairwise prediction on graphs through node-centric and pair-centric perspectives, with pre-trained pair embeddings to facilitate pair-centric modeling.
Rationalizing Medical Relation Prediction from Corpus-level Statistics
ACL 2020 (Main, Long)
A self-interpretable framework to rationalize neural relation prediction based on corpus-level statistics, inspired by human cognitive theory about recall and recognition, providing structured knowledge triplets as rationales.
SurfCon: Synonym Discovery on Privacy-Aware Clinical Data
KDD 2019 (Research Track, Long, Oral)
Discovers structured knowledge, synonyms, from privacy-aware clinical text corpus, leveraging both surface form and context information to discover out-of-distribution synonyms.
Knowledge Transfer between Structured and Unstructured Sources for Complex Question Answering
NAACL 2022 SUKI Workshop
Studies knowledge transfer for multi-hop reasoning between structured (KB) and unstructured (text) knowledge. SimultQA unifies KBQA and TextQA to study how reasoning transfers between knowledge sources.
A Comprehensive Study of StaQC for Deep Code Summarization
KDD 2018 Deep Learning Day Spotlight
Examines three popular datasets mined from Stack Overflow on code summarization, showing that StaQC achieves substantially better results.
Efficient Training and Adaptation of Foundation Models
Demystifying Training-Time Augmentation for Data-Constrained Language Model Pretraining
In submission
A systematic study of training-time data augmentation for pretraining language models in the data-constrained, compute-abundant regime.
Self-MoE: Towards Compositional Large Language Models with Self-Specialized Experts
ICLR 2025
Transforms monolithic LLMs into modular systems with self-specialized experts for compositional capabilities.
Multitask Prompt Tuning Enables Parameter-Efficient Transfer Learning
ICLR 2023
Multitask Prompt Tuning (MPT) exploits rich cross-task knowledge for efficient and generalizable transfer learning through novel prompt decomposition and distillation.
ToolkenGPT: Augmenting Frozen Language Models with Massive Tools via Tool Embeddings
NeurIPS 2023 Oral (Top 2%) Best Paper @ SoCal NLP 2023
Augments LLMs with massive tools/APIs by representing tools as tokens, enabling tool calls as naturally as generating words. Plugging in new tools is as easy as learning embeddings.
Frustratingly Simple Entity Tracking with Effective Use of Multi-Task Learning Models
EACL 2023 (Main)
Shows how to transfer multi-task knowledge from pre-training to niche downstream tasks like entity tracking, achieving SOTA by fine-tuning T5 with specialized QA prompts and task-specific decoding.
Pancake: Hierarchical Memory System for Multi-Agent LLM Serving
In submission to OSDI 2026
A hierarchical memory system designed for efficient multi-agent LLM serving.
Human-Aligned Learning and Evaluation
MemProbe: Probing Long-Term Agent Memory via Hidden User-State Recovery
In submission
A framework that probes long-term agent memory by recovering the hidden user states it has implicitly absorbed.
Mind2Dialogue: State-Aware User Simulation for Theory-of-Mind and Personalization
In submission
A state-aware user simulator for enhancing theory-of-mind and personalization in LLMs.
DeepPersona: A Generative Engine for Scaling Deep Synthetic Personas
Spotlight at NeurIPS 2025 LAW Workshop; In submission to ICLR 2026
A generative engine for creating deep synthetic personas that enable realistic human simulation at scale.
FIRE-Bench: Evaluating Research Agents on the Rediscovery of Scientific Insights
ICML 2026
The first benchmark for reliably evaluating research agents on full-cycle scientific (re-)discovery, with verifiable evaluation of insight rediscovery.
Decentralized Arena: Towards Democratic and Scalable Automatic Evaluation of Language Models
In submission to ACL 2026
Democratic LLM benchmarking where models judge each other for scalable and fair evaluation.
Dynamic Rewarding with Prompt Optimization Enables Tuning-free Self-Alignment of Language Models
EMNLP 2024 (Main, Long)
First tuning-free method for self-aligning LLMs with human preferences through dynamic rewarding and prompt optimization.
Bootstrapping a User-Centered Task-Oriented Dialogue System
Alexa Prize TaskBot Challenge 2021 3rd Place Winner
TacoBot, a task-oriented dialogue system for cooking and home improvement tasks. Proposes data augmentation methods including GPT-3 simulation to bootstrap neural dialogue systems into new domains.
Roll Up Your Sleeves: Working with a Collaborative and Engaging Task-Oriented Dialogue System
SIGDIAL 2023
A collaborative and engaging task-oriented dialogue system for multi-step cooking and home improvement tasks.
Scientific Foundation Models and AI Scientists
TreeScientist: Budget-Constrained Exploration for Autonomous Research
In submission
A budget-aware tree-structured exploration strategy that lets autonomous research agents allocate compute and trials adaptively.
HypoEvolve: When Genetic Algorithm Meets Multi-Agents to Accelerate Hypothesis Discovery
In submission
A novel approach combining genetic algorithms with multi-agent systems for automated scientific hypothesis discovery.
TritonDFT: Automating DFT with a Multi-Agent Framework
In submission
A multi-agent framework for automating Density Functional Theory (DFT) calculations in materials science.
scPilot: Large Language Model Reasoning Toward Automated Single-Cell Analysis and Discovery
NeurIPS 2025
The first omics-native reasoning agent that grounds LLMs in raw single-cell data for automated analysis and biological discovery.
CellMaster: Collaborative Cell Type Annotation in Single-Cell Analysis
In submission
A collaborative AI scientist agent for automated cell type annotation in single-cell transcriptomics analysis.
Atlas-Guided Discovery of Transcription Factors for T Cell Programming
Nature 2025 In Press
Contributed TaijiChat, a Paper Copilot for multi-omics discovery of transcription factors for T cell programming.
A Foundation Model of Cancer Genotype Enables Precise Predictions of Therapeutic Response
Cancer Discovery 2026 In Press IF: 33.3
The first genomics foundation model of cancer mutations, enabling precise predictions of therapeutic response.
Graph Embedding on Biomedical Networks: Methods, Applications, and Evaluations
Bioinformatics, Volume 36, Issue 4, February 2020
Benchmarks 11 representative graph embedding methods on five important biomedical tasks, verifying effectiveness and providing general guidelines for their usage.
Rationalizing Medical Relation Prediction from Corpus-level Statistics
ACL 2020 (Main, Long)
A self-interpretable framework to rationalize neural relation prediction based on corpus-level statistics, providing structured knowledge triplets as rationales.
SurfCon: Synonym Discovery on Privacy-Aware Clinical Data
KDD 2019 (Research Track, Long, Oral)
Discovers synonyms from privacy-aware clinical text corpus using both surface form and context information.